Tutorial on edu-convokit for the NCTE dataset
Welcome to the tutorial on edu-convokit for the NCTE dataset. This tutorial will walk you through the process of using edu-convokit to pre-process, annotate and analyze the NCTE dataset.
If you are looking for a tutorial on the individual components of edu-convokit, please refer to the following tutorials to get started:
This tutorial will use all of the components!
Installation
Let’s start by installing edu-convokit and importing the necessary modules.
[ ]:
!pip install edu-convokit
Collecting git+https://github.com/rosewang2008/edu-convokit.git
Cloning https://github.com/rosewang2008/edu-convokit.git to /tmp/pip-req-build-ncsfguml
Running command git clone --filter=blob:none --quiet https://github.com/rosewang2008/edu-convokit.git /tmp/pip-req-build-ncsfguml
Resolved https://github.com/rosewang2008/edu-convokit.git to commit 5c1128c8f94d7574bc61cc56f29ce64bdca4ae30
Preparing metadata (setup.py) ... done
Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.66.1)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.23.5)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.11.4)
Requirement already satisfied: nltk in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.8.1)
Requirement already satisfied: torch in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (2.1.0+cu121)
Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.35.2)
Collecting clean-text (from edu-convokit==0.0.1)
Downloading clean_text-0.6.0-py3-none-any.whl (11 kB)
Requirement already satisfied: openpyxl in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.1.2)
Requirement already satisfied: spacy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.6.1)
Requirement already satisfied: gensim in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.3.2)
Collecting num2words==0.5.10 (from edu-convokit==0.0.1)
Downloading num2words-0.5.10-py3-none-any.whl (101 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 101.6/101.6 kB 1.1 MB/s eta 0:00:00
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.2.2)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.7.1)
Requirement already satisfied: seaborn in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (0.12.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.5.3)
Collecting docopt>=0.6.2 (from num2words==0.5.10->edu-convokit==0.0.1)
Downloading docopt-0.6.2.tar.gz (25 kB)
Preparing metadata (setup.py) ... done
Collecting emoji<2.0.0,>=1.0.0 (from clean-text->edu-convokit==0.0.1)
Downloading emoji-1.7.0.tar.gz (175 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 175.4/175.4 kB 3.3 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting ftfy<7.0,>=6.0 (from clean-text->edu-convokit==0.0.1)
Downloading ftfy-6.1.3-py3-none-any.whl (53 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 53.4/53.4 kB 5.0 MB/s eta 0:00:00
Requirement already satisfied: smart-open>=1.8.1 in /usr/local/lib/python3.10/dist-packages (from gensim->edu-convokit==0.0.1) (6.4.0)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (4.46.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (23.2)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (9.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (2.8.2)
Requirement already satisfied: click in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (8.1.7)
Requirement already satisfied: joblib in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (1.3.2)
Requirement already satisfied: regex>=2021.8.3 in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (2023.6.3)
Requirement already satisfied: et-xmlfile in /usr/local/lib/python3.10/dist-packages (from openpyxl->edu-convokit==0.0.1) (1.1.0)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas->edu-convokit==0.0.1) (2023.3.post1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->edu-convokit==0.0.1) (3.2.0)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.0.12)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.0.5)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.0.10)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.0.8)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.0.9)
Requirement already satisfied: thinc<8.2.0,>=8.1.8 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (8.1.12)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.1.2)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.4.8)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.0.10)
Requirement already satisfied: typer<0.10.0,>=0.3.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (0.9.0)
Requirement already satisfied: pathy>=0.10.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (0.10.3)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.31.0)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.10.13)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.1.2)
Requirement already satisfied: setuptools in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (67.7.2)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.3.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (3.13.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (4.5.0)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (1.12)
Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (3.2.1)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (2023.6.0)
Requirement already satisfied: triton==2.1.0 in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (2.1.0)
Requirement already satisfied: huggingface-hub<1.0,>=0.16.4 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.19.4)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (6.0.1)
Requirement already satisfied: tokenizers<0.19,>=0.14 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.15.0)
Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.4.1)
Requirement already satisfied: wcwidth<0.3.0,>=0.2.12 in /usr/local/lib/python3.10/dist-packages (from ftfy<7.0,>=6.0->clean-text->edu-convokit==0.0.1) (0.2.12)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->edu-convokit==0.0.1) (1.16.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (2023.11.17)
Requirement already satisfied: blis<0.8.0,>=0.7.8 in /usr/local/lib/python3.10/dist-packages (from thinc<8.2.0,>=8.1.8->spacy->edu-convokit==0.0.1) (0.7.11)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in /usr/local/lib/python3.10/dist-packages (from thinc<8.2.0,>=8.1.8->spacy->edu-convokit==0.0.1) (0.1.4)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->spacy->edu-convokit==0.0.1) (2.1.3)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch->edu-convokit==0.0.1) (1.3.0)
Building wheels for collected packages: edu-convokit, docopt, emoji
Building wheel for edu-convokit (setup.py) ... done
Created wheel for edu-convokit: filename=edu_convokit-0.0.1-py3-none-any.whl size=24909 sha256=257e42119604caf33f42981c96e1407bdb7733bc8082e870a022def70e9310c2
Stored in directory: /tmp/pip-ephem-wheel-cache-vp1s8qol/wheels/29/43/ec/d2472df0eb2af8f1e7d67d0710a4b3eb93fe983b15f8d7b841
Building wheel for docopt (setup.py) ... done
Created wheel for docopt: filename=docopt-0.6.2-py2.py3-none-any.whl size=13706 sha256=f02c574964e73b6f4c06b4c638b3da8b4cda7eac2dfe1604b8aff6f95701bfb3
Stored in directory: /root/.cache/pip/wheels/fc/ab/d4/5da2067ac95b36618c629a5f93f809425700506f72c9732fac
Building wheel for emoji (setup.py) ... done
Created wheel for emoji: filename=emoji-1.7.0-py3-none-any.whl size=171033 sha256=0a5d69f4ac14f376271ac4011aefc99eb821dcd5b2584b28eefd54bca2b8cfc0
Stored in directory: /root/.cache/pip/wheels/31/8a/8c/315c9e5d7773f74b33d5ed33f075b49c6eaeb7cedbb86e2cf8
Successfully built edu-convokit docopt emoji
Installing collected packages: emoji, docopt, num2words, ftfy, clean-text, edu-convokit
Successfully installed clean-text-0.6.0 docopt-0.6.2 edu-convokit-0.0.1 emoji-1.7.0 ftfy-6.1.3 num2words-0.5.10
[ ]:
from edu_convokit.preprocessors import TextPreprocessor
from edu_convokit.annotation import Annotator
from edu_convokit.analyzers import (
QualitativeAnalyzer,
QuantitativeAnalyzer,
LexicalAnalyzer,
TemporalAnalyzer,
GPTConversationAnalyzer
)
# For helping us load data
from edu_convokit import utils
import os
import tqdm
WARNING:root:Since the GPL-licensed package `unidecode` is not installed, using Python's `unicodedata` package which yields worse results.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
📑 Data
Let’s download the dataset under raw_data/. Note we’re only download a subsample of the NCTE dataset for this tutorial; this cuts down the annotation time. If you would like to annotate the entire dataset, feel free to upload the entire dataset to this Colab!
[ ]:
# We will put the data here:
DATA_DIR = "raw_data"
!mkdir -p $DATA_DIR
# We will put the annotated data here:
ANNOTATIONS_DIR = "annotations"
!mkdir -p $ANNOTATIONS_DIR
# # Download the data
!wget "https://raw.githubusercontent.com/rosewang2008/edu-convokit/master/data/ncte.zip"
# # Unzip the data
!unzip -n -q ncte.zip -d $DATA_DIR
# Data directory is then raw_data/talkmoves
DATA_DIR = "raw_data/ncte"
--2023-12-30 10:54:18-- https://raw.githubusercontent.com/rosewang2008/edu-convokit/master/data/ncte.zip
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.109.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 346717 (339K) [application/zip]
Saving to: ‘ncte.zip’
ncte.zip 100%[===================>] 338.59K --.-KB/s in 0.03s
2023-12-30 10:54:19 (9.57 MB/s) - ‘ncte.zip’ saved [346717/346717]
[ ]:
# We'll set the important variables specific to this dataset. If you open one of the files, you'll see that the
# speaker and text columns are defined as:
TEXT_COLUMN = "text"
SPEAKER_COLUMN = "speaker"
# We will also define the annotation columns.
# For the purposes of this tutorial, we will only be using talktime, student_reasoning, and uptake.
TALK_TIME_COLUMN = "talktime"
STUDENT_REASONING_COLUMN = "student_reasoning"
UPTAKE_COLUMN = "uptake"
One thing that will be important is knowing how the teacher/tutor and student are represented in the dataset. Let’s load some examples and see how they are represented.
[ ]:
files = os.listdir(DATA_DIR)
files = [os.path.join(DATA_DIR, f) for f in files if utils.is_valid_file_extension(f)]
df = utils.merge_dataframes_in_list(files)
print(df[SPEAKER_COLUMN].unique())
df.head()
['teacher' 'multiple students' 'student']
| text | speaker | talktime_words | math_density | uptake | student_reasoning | focusing_questions | |
|---|---|---|---|---|---|---|---|
| 0 | Okay. I think it’s working. Alright, so the ... | teacher | 17 | 0 | NaN | NaN | 0.0 |
| 1 | Yes. | multiple students | 1 | 0 | NaN | NaN | NaN |
| 2 | Student M, you don’t have your homework? | teacher | 7 | 0 | NaN | NaN | 0.0 |
| 3 | No. | student | 1 | 0 | NaN | NaN | NaN |
| 4 | Did you hand it in? | teacher | 5 | 0 | NaN | NaN | 0.0 |
There are two speakers: one is the teacher and the other is the student/multiple students. Let’s defined these variables as well.
[ ]:
STUDENT_SPEAKER = ['student', 'multiple students']
TEACHER_SPEAKER = 'teacher'
📝 Text Pre-Processing and Annotation
Let’s first preprocess and annotate the dataset with edu-convokit. The following section will:
Read each file in the dataset and preprocess it using
edu-convokit’sPreprocessor.Then, annotate the file using
edu-convokit’sAnnotatorfor talktime, student reasoning and uptake.Finally, save the annotated file under
data/annotated/.
Let’s get started!
[ ]:
# Initialize the preprocessor and annotator
processor = TextPreprocessor()
annotator = Annotator()
# This takes about 7 minutes on Colab, CPU
# Though this time varies depending on bandwidth
for filename in tqdm.tqdm(os.listdir(DATA_DIR)):
if utils.is_valid_file_extension(filename):
df = utils.load_data(os.path.join(DATA_DIR, filename))
# Preprocess the data. We're just going to merge the utterances of the same speaker together and directly update the dataframe.
df = processor.merge_utterances_from_same_speaker(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
target_text_column=TEXT_COLUMN
)
# Now we're going to annotate the data.
df = annotator.get_talktime(
df=df,
text_column=TEXT_COLUMN,
output_column=TALK_TIME_COLUMN
)
df = annotator.get_student_reasoning(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
output_column=STUDENT_REASONING_COLUMN,
# We just want to annotate the student utterances. So we're going to specify the speaker value as STUDENT_SPEAKER.
speaker_value=STUDENT_SPEAKER
)
df = annotator.get_uptake(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
output_column=UPTAKE_COLUMN,
# We want to annotate the teacher's uptake of the student's utterances.
# So we're looking for instances where the student first speaks, then the teacher speaks.
speaker1=STUDENT_SPEAKER,
speaker2=TEACHER_SPEAKER
)
# And we're done! Let's now save the annotated data as a csv file.
filename = filename.split(".")[0] + ".csv"
df.to_csv(os.path.join(ANNOTATIONS_DIR, filename), index=False)
0%| | 0/29 [00:00<?, ?it/s]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
3%|▎ | 1/29 [00:26<12:22, 26.51s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
7%|▋ | 2/29 [00:35<07:16, 16.17s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
10%|█ | 3/29 [00:48<06:25, 14.81s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
14%|█▍ | 4/29 [01:04<06:17, 15.08s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
17%|█▋ | 5/29 [01:19<06:05, 15.24s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
21%|██ | 6/29 [01:29<05:04, 13.25s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
24%|██▍ | 7/29 [01:48<05:37, 15.36s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
28%|██▊ | 8/29 [01:55<04:24, 12.58s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
31%|███ | 9/29 [02:01<03:33, 10.69s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
34%|███▍ | 10/29 [02:21<04:17, 13.53s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
38%|███▊ | 11/29 [02:39<04:26, 14.78s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
41%|████▏ | 12/29 [02:50<03:51, 13.63s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
45%|████▍ | 13/29 [03:03<03:33, 13.36s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
48%|████▊ | 14/29 [03:11<02:56, 11.73s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
52%|█████▏ | 15/29 [03:27<03:02, 13.02s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
55%|█████▌ | 16/29 [03:47<03:16, 15.13s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
59%|█████▊ | 17/29 [03:55<02:35, 12.99s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
62%|██████▏ | 18/29 [04:10<02:32, 13.84s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
66%|██████▌ | 19/29 [04:38<02:58, 17.83s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
69%|██████▉ | 20/29 [04:54<02:36, 17.35s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
72%|███████▏ | 21/29 [05:06<02:06, 15.76s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
76%|███████▌ | 22/29 [05:16<01:39, 14.18s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
79%|███████▉ | 23/29 [05:21<01:07, 11.31s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
83%|████████▎ | 24/29 [05:41<01:09, 13.98s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
86%|████████▌ | 25/29 [05:56<00:56, 14.10s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
90%|████████▉ | 26/29 [06:06<00:38, 12.88s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
93%|█████████▎| 27/29 [06:18<00:25, 12.71s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
97%|█████████▋| 28/29 [06:23<00:10, 10.38s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
100%|██████████| 29/29 [06:42<00:00, 13.89s/it]
Analysis
Now that we have annotated the dataset, let’s analyze it using edu-convokit’s Analyzer. We’ll be doing the following:
We’ll use
QualitativeAnalyzerto look at some examples of the talktime, student reasoning and uptake annotations.We’ll use
QuantitativeAnalyzerto look at the aggregate statistics of the talktime, student reasoning and uptake annotations.We’ll use
LexicalAnalyzerto compare the student and tutor’s vocabulary.We’ll use
TemporalAnalyzerto look at the temporal trends of the talktime, student reasoning and uptake annotations.
Let’s get started!!!
🔍 Qualitative Analysis
[ ]:
# We're going to look at examples from the entire dataset.
qualitative_analyzer = QualitativeAnalyzer(data_dir=ANNOTATIONS_DIR)
# Examples of talktime. Will show random examples from the dataset.
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=TALK_TIME_COLUMN,
)
talktime: 17
>> teacher: Okay. I think it’s working. Alright, so the first thing – everyone got their homework back, correct?
talktime: 17
>> teacher: Okay. That could be your problem. Student [G], do you have a question? Student N, sit up.
talktime: 17
>> student: A year has 52 weeks so 52 times 4 equals 52 times 2 plus 52 times 2.
talktime: 1
>> multiple students: Yes.
talktime: 1
>> student: No.
talktime: 1
>> student: Yes.
talktime: 7
>> teacher: Student M, you don’t have your homework?
talktime: 7
>> student: [Inaudible]. She just didn’t really – oh.
talktime: 7
>> student: 60 times 11; and 3 times 11.
[ ]:
# Examples of student reasoning. Let's look at positive examples:
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=STUDENT_REASONING_COLUMN,
feature_value=1.0,
)
student_reasoning: 1.0
>> student: You could – so 76 times 10 is double the final problem so you –
student_reasoning: 1.0
>> student: They all will add up to a whole.
student_reasoning: 1.0
>> student: Because I know that three-sixths is equivalent to one-half in fractions.
[ ]:
# We can also look at negative examples:
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=STUDENT_REASONING_COLUMN,
feature_value=0.0,
)
student_reasoning: 0.0
>> student: No. This is Student D.D.; this is Student D.C.
student_reasoning: 0.0
>> student: Do you want me to go that way?
student_reasoning: 0.0
>> student: I did 63 times 10 equals 630 and then 63 to that equals [Inaudible] and then I got, I got 693.
[ ]:
# Examples of uptake.
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=UPTAKE_COLUMN,
# I want to look at positive examples of uptake (uptake = 1.0)
feature_value=1.0,
# ... and look at the previous student utterance (show_k_previous_lines = 1).
# This is interesting because it will show us how the teacher is responding to the student's utterance.
show_k_previous_lines=1,
)
uptake: 1.0
student: No. This is Student D.D.; this is Student D.C.
>> teacher: Okay, give Student D.C. his. And what are you on Student D?
uptake: 1.0
student: Can I leave my desk?
>> teacher: You may go get it. Student A, can you please get Student N’s folder out of her desk, and Student J, can you please turn off a light.
uptake: 1.0
student: 63 times 10 is 630.
>> teacher: 630. Good. Um, Student H, what’s 60 times 11?
📊 Quantitative Analysis
[ ]:
quantitative_analyzer = QuantitativeAnalyzer(data_dir=ANNOTATIONS_DIR)
# Let's plot the talk time ratio between the speakers.
quantitative_analyzer.plot_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
# Proportion of talk time for each speaker.
value_as="prop"
)
# We can also print the statistics:
quantitative_analyzer.print_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
# Proportion of talk time for each speaker.
value_as="prop"
)

talktime
Proportion statistics
count mean std min 25% 50% 75% max
speaker
multiple students 29.0 0.003755 0.004297 0.000127 0.000892 0.002291 0.004942 0.017520
student 29.0 0.145835 0.054895 0.040153 0.105824 0.139083 0.176111 0.279475
teacher 29.0 0.850410 0.056019 0.709941 0.821598 0.858346 0.890292 0.959623
<Figure size 640x480 with 0 Axes>
[ ]:
# What about the student reasoning? How often does the student use reasoning?
quantitative_analyzer.plot_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
# We change this to "avg" because we're now looking at within-speaker statistics.
value_as="avg",
# We can set the y-axis limits to [0, 1] because the student reasoning column is a binary column.
yrange=(0, 1)
)
# We can also print the statistics:
quantitative_analyzer.print_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg"
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
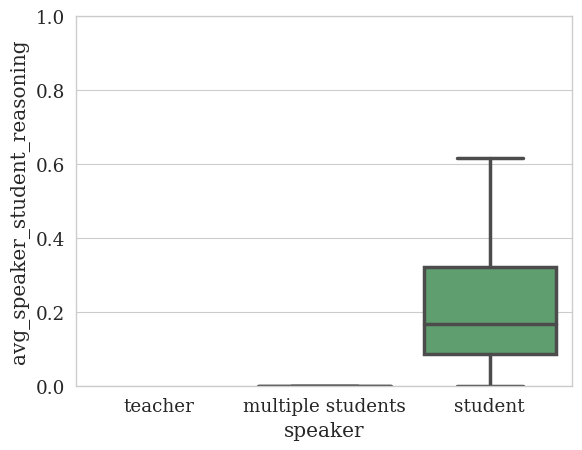
student_reasoning
Average statistics
count mean std min 25% 50% 75% max
speaker
multiple students 1.0 0.000000 NaN 0.0 0.000000 0.000000 0.000000 0.000000
student 29.0 0.208633 0.163928 0.0 0.085106 0.166667 0.321429 0.615385
teacher 0.0 NaN NaN NaN NaN NaN NaN NaN
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
<Figure size 640x480 with 0 Axes>
Note, the tutor has no student_reasoning because we did not annotate the tutor’s utterances for student reasoning. We can easily remove the tutor from the plot by dropping na values:
[ ]:
quantitative_analyzer.plot_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
yrange=(0, 1),
dropna=True
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,

<Figure size 640x480 with 0 Axes>
[ ]:
# Finally, let's look at the tutor's uptake of the student's utterances.
quantitative_analyzer.plot_statistics(
feature_column=UPTAKE_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
yrange=(0, 1),
dropna=True
)

<Figure size 640x480 with 0 Axes>
💬 Lexical Analysis
[ ]:
lexical_analyzer = LexicalAnalyzer(data_dir=ANNOTATIONS_DIR)
# Let's look at the most common words per speaker in the dataset.
lexical_analyzer.print_word_frequency(
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
# We want to look at the top 10 words per speaker.
topk=10,
# Let's also format the text (e.g., remove punctuation, lowercase the text, etc.)
run_text_formatting=True
)
Top Words By Speaker
teacher
student: 2127
okay: 2100
one: 1811
right: 1428
times: 1243
going: 952
know: 707
two: 650
good: 618
want: 569
multiple students
yes: 101
inaudible: 89
yeah: 29
percent: 18
two: 10
one: 7
half: 6
three: 5
whole: 4
unlike: 4
student
inaudible: 1453
times: 501
one: 420
two: 242
yeah: 225
three: 195
like: 180
yes: 177
four: 175
percent: 155
The language between the two looks pretty similar. Let’s run a log-odds analysis to see what words that are more likely to be used by the tutor vs. student.
[ ]:
# This returns the merged dataframe of the annotated files in DATA_DIR.
df = lexical_analyzer.get_df()
# We want to create two groups of df: one for the student and one for the tutor.
student_df = df[df[SPEAKER_COLUMN].isin(STUDENT_SPEAKER)]
tutor_df = df[df[SPEAKER_COLUMN] == TEACHER_SPEAKER]
# Now we can run the log-odds analysis:
lexical_analyzer.plot_log_odds(
df1=student_df,
df2=tutor_df,
text_column1=TEXT_COLUMN,
text_column2=TEXT_COLUMN,
# Let's name the df groups to show on the plot
group1_name="Student",
group2_name="Teacher",
# Let's also run the text formatting
run_text_formatting=True,
)

<Figure size 640x480 with 0 Axes>
[ ]:
# We might also be interested in other n-grams. Let's look at the top 10 bigrams per speaker.
lexical_analyzer.plot_log_odds(
df1=student_df,
df2=tutor_df,
text_column1=TEXT_COLUMN,
text_column2=TEXT_COLUMN,
group1_name="Student",
group2_name="Tutor",
run_text_formatting=True,
# n-grams:
run_ngrams=True,
n=2,
topk=10
)

<Figure size 640x480 with 0 Axes>
📈 Temporal Analysis
Let’s look at the temporal trends of the talktime, student reasoning and uptake annotations!
[ ]:
temporal_analyzer = TemporalAnalyzer(data_dir=ANNOTATIONS_DIR)
# First let's look at the talk time ratio between the speakers over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="prop",
# Let's create 10 bins for the x-axis.
num_bins=10
)

<Figure size 640x480 with 0 Axes>
[ ]:
# Now student reasoning over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
# Let's create 5 bins for the x-axis.
num_bins=10,
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/temporal_analyzer.py:57: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,

<Figure size 640x480 with 0 Axes>
[ ]:
# Finally, let's look at the tutor's uptake of the student's utterances over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=UPTAKE_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
# Let's create 5 bins for the x-axis.
num_bins=10,
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/temporal_analyzer.py:57: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
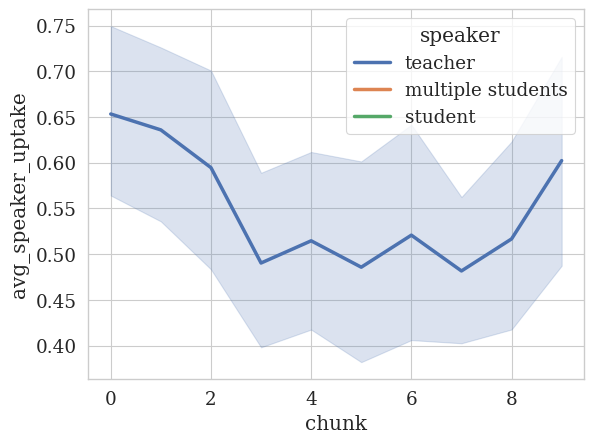
<Figure size 640x480 with 0 Axes>
🤖 GPT Conversation Analysis
Finally, we can also use edu-convokit to analyze the conversations using GPT models. Let’s use GPT4 to summarize one of the conversations.
[1]:
import os
# Remember to never share your API key!
os.environ["OPENAI_API_KEY"]="YOUR_API_KEY"
[ ]:
df = utils.load_data(os.path.join(DATA_DIR, "3.csv"))
# We're going to use the GPTConversationAnalyzer to summarize the conversations.
# First, let's look at the prompt for summarization.
analyzer = GPTConversationAnalyzer()
prompt = analyzer.preview_prompt(
df=df,
prompt_name="summarize",
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
model="gpt-4",
# I'm going to only use the first quarter of the transcript
# Because the transcript is very long
keep_transcript_fraction=0.25,
)
💡 We can see that the prompt is set up to summarize the transcript. If you are comfortable with the prompt, you can now prompt the model on that prompt with run_prompt
[ ]:
prompt, response = analyzer.run_prompt(
df=df,
prompt_name="summarize",
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
model="gpt-4",
keep_transcript_fraction=0.25,
)
print(response)
📚 Conclusions and Next Steps
Great! From this tutorial, we learned how to use edu-convokit to preprocess, annotate and analyze the Amber dataset. We saw how very simple principles built into edu-convokit can be used to analyze the dataset and gain insights into the data from various perspectives (qualitative, quantitative, lexical and temporal).
Other resources you can check out include:
`edu-convokitdocumentation <https://edu-convokit.readthedocs.io/en/latest/index.html>`__`edu-convokitGitHub repository <https://github.com/rosewang2008/edu-convokit/tree/main>`__
If you have any questions, please feel free to reach out to us on `edu-convokit’s GitHub <https://github.com/rosewang2008/edu-convokit>`__.
👋 Happy exploring your data with edu-convokit!
[ ]: