Tutorial on edu-convokit for the Amber dataset
Welcome to the tutorial on edu-convokit for the Amber dataset. This tutorial will walk you through the process of using edu-convokit to pre-process, annotate and analyze the Amber dataset.
If you are looking for a tutorial on the individual components of edu-convokit, please refer to the following tutorials to get started:
This tutorial will use all of the components!
Installation
Let’s start by installing edu-convokit and importing the necessary modules.
[ ]:
!pip install git+https://github.com/rosewang2008/edu-convokit.git
Collecting git+https://github.com/rosewang2008/edu-convokit.git
Cloning https://github.com/rosewang2008/edu-convokit.git to /tmp/pip-req-build-repqq1x3
Running command git clone --filter=blob:none --quiet https://github.com/rosewang2008/edu-convokit.git /tmp/pip-req-build-repqq1x3
Resolved https://github.com/rosewang2008/edu-convokit.git to commit 2c36eabaf3d4dff1d8c1e89ae4f175ec80617f7e
Preparing metadata (setup.py) ... done
Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.66.1)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.23.5)
Requirement already satisfied: scipy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.11.4)
Requirement already satisfied: nltk in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.8.1)
Requirement already satisfied: torch in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (2.1.0+cu121)
Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.35.2)
Collecting clean-text (from edu-convokit==0.0.1)
Downloading clean_text-0.6.0-py3-none-any.whl (11 kB)
Requirement already satisfied: openpyxl in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.1.2)
Requirement already satisfied: spacy in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.6.1)
Requirement already satisfied: gensim in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (4.3.2)
Collecting num2words==0.5.10 (from edu-convokit==0.0.1)
Downloading num2words-0.5.10-py3-none-any.whl (101 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 101.6/101.6 kB 1.3 MB/s eta 0:00:00
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.2.2)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (3.7.1)
Requirement already satisfied: seaborn in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (0.12.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (from edu-convokit==0.0.1) (1.5.3)
Collecting docopt>=0.6.2 (from num2words==0.5.10->edu-convokit==0.0.1)
Downloading docopt-0.6.2.tar.gz (25 kB)
Preparing metadata (setup.py) ... done
Collecting emoji<2.0.0,>=1.0.0 (from clean-text->edu-convokit==0.0.1)
Downloading emoji-1.7.0.tar.gz (175 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 175.4/175.4 kB 3.3 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting ftfy<7.0,>=6.0 (from clean-text->edu-convokit==0.0.1)
Downloading ftfy-6.1.3-py3-none-any.whl (53 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 53.4/53.4 kB 4.3 MB/s eta 0:00:00
Requirement already satisfied: smart-open>=1.8.1 in /usr/local/lib/python3.10/dist-packages (from gensim->edu-convokit==0.0.1) (6.4.0)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (4.46.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (23.2)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (9.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->edu-convokit==0.0.1) (2.8.2)
Requirement already satisfied: click in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (8.1.7)
Requirement already satisfied: joblib in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (1.3.2)
Requirement already satisfied: regex>=2021.8.3 in /usr/local/lib/python3.10/dist-packages (from nltk->edu-convokit==0.0.1) (2023.6.3)
Requirement already satisfied: et-xmlfile in /usr/local/lib/python3.10/dist-packages (from openpyxl->edu-convokit==0.0.1) (1.1.0)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas->edu-convokit==0.0.1) (2023.3.post1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->edu-convokit==0.0.1) (3.2.0)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.0.12)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.0.5)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.0.10)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.0.8)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.0.9)
Requirement already satisfied: thinc<8.2.0,>=8.1.8 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (8.1.12)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.1.2)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.4.8)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.0.10)
Requirement already satisfied: typer<0.10.0,>=0.3.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (0.9.0)
Requirement already satisfied: pathy>=0.10.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (0.10.3)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (2.31.0)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (1.10.13)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.1.2)
Requirement already satisfied: setuptools in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (67.7.2)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in /usr/local/lib/python3.10/dist-packages (from spacy->edu-convokit==0.0.1) (3.3.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (3.13.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (4.5.0)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (1.12)
Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (3.2.1)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (2023.6.0)
Requirement already satisfied: triton==2.1.0 in /usr/local/lib/python3.10/dist-packages (from torch->edu-convokit==0.0.1) (2.1.0)
Requirement already satisfied: huggingface-hub<1.0,>=0.16.4 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.19.4)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (6.0.1)
Requirement already satisfied: tokenizers<0.19,>=0.14 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.15.0)
Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from transformers->edu-convokit==0.0.1) (0.4.1)
Requirement already satisfied: wcwidth<0.3.0,>=0.2.12 in /usr/local/lib/python3.10/dist-packages (from ftfy<7.0,>=6.0->clean-text->edu-convokit==0.0.1) (0.2.12)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->edu-convokit==0.0.1) (1.16.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests<3.0.0,>=2.13.0->spacy->edu-convokit==0.0.1) (2023.11.17)
Requirement already satisfied: blis<0.8.0,>=0.7.8 in /usr/local/lib/python3.10/dist-packages (from thinc<8.2.0,>=8.1.8->spacy->edu-convokit==0.0.1) (0.7.11)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in /usr/local/lib/python3.10/dist-packages (from thinc<8.2.0,>=8.1.8->spacy->edu-convokit==0.0.1) (0.1.4)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->spacy->edu-convokit==0.0.1) (2.1.3)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch->edu-convokit==0.0.1) (1.3.0)
Building wheels for collected packages: edu-convokit, docopt, emoji
Building wheel for edu-convokit (setup.py) ... done
Created wheel for edu-convokit: filename=edu_convokit-0.0.1-py3-none-any.whl size=24909 sha256=3e71c896ae285efe3570837daebb1e05f2855b510db11ebff66b503b2e1e7939
Stored in directory: /tmp/pip-ephem-wheel-cache-hve93bfu/wheels/29/43/ec/d2472df0eb2af8f1e7d67d0710a4b3eb93fe983b15f8d7b841
Building wheel for docopt (setup.py) ... done
Created wheel for docopt: filename=docopt-0.6.2-py2.py3-none-any.whl size=13706 sha256=cd3e6e02d727798745a61ddf5b510db593fc4f6b164c6f242e607477dfb090ce
Stored in directory: /root/.cache/pip/wheels/fc/ab/d4/5da2067ac95b36618c629a5f93f809425700506f72c9732fac
Building wheel for emoji (setup.py) ... done
Created wheel for emoji: filename=emoji-1.7.0-py3-none-any.whl size=171033 sha256=a5a47ae4916b773f7e0049304c63c50d066bee6292e0860693efecda135b802f
Stored in directory: /root/.cache/pip/wheels/31/8a/8c/315c9e5d7773f74b33d5ed33f075b49c6eaeb7cedbb86e2cf8
Successfully built edu-convokit docopt emoji
Installing collected packages: emoji, docopt, num2words, ftfy, clean-text, edu-convokit
Successfully installed clean-text-0.6.0 docopt-0.6.2 edu-convokit-0.0.1 emoji-1.7.0 ftfy-6.1.3 num2words-0.5.10
[ ]:
from edu_convokit.preprocessors import TextPreprocessor
from edu_convokit.annotation import Annotator
from edu_convokit.analyzers import (
QualitativeAnalyzer,
QuantitativeAnalyzer,
LexicalAnalyzer,
TemporalAnalyzer
)
# For helping us load data
from edu_convokit import utils
import os
import tqdm
WARNING:root:Since the GPL-licensed package `unidecode` is not installed, using Python's `unicodedata` package which yields worse results.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
📑 Data
Let’s download the dataset under raw_data/.
[ ]:
# We will put the data here:
DATA_DIR = "raw_data"
!mkdir -p $DATA_DIR
# We will put the annotated data here:
ANNOTATIONS_DIR = "annotations"
!mkdir -p $ANNOTATIONS_DIR
# # Download the data
!wget "https://raw.githubusercontent.com/rosewang2008/edu-convokit/master/data/amber.zip"
# # Unzip the data
!unzip -n -q amber.zip -d $DATA_DIR
# Data directory is then raw_data/amber
DATA_DIR = "raw_data/amber"
--2023-12-30 10:47:59-- https://raw.githubusercontent.com/rosewang2008/edu-convokit/master/data/amber.zip
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 547335 (535K) [application/zip]
Saving to: ‘amber.zip’
amber.zip 100%[===================>] 534.51K --.-KB/s in 0.04s
2023-12-30 10:47:59 (11.9 MB/s) - ‘amber.zip’ saved [547335/547335]
[ ]:
# We'll set the important variables specific to this dataset. If you open one of the files, you'll see that the
# speaker and text columns are defined as:
TEXT_COLUMN = "dialogue"
SPEAKER_COLUMN = "speaker"
# We will also define the annotation columns.
# For the purposes of this tutorial, we will only be using talktime, student_reasoning, and uptake.
TALK_TIME_COLUMN = "talktime"
STUDENT_REASONING_COLUMN = "student_reasoning"
UPTAKE_COLUMN = "uptake"
One thing that will be important is knowing how the teacher/tutor and student are represented in the dataset. Let’s load some examples and see how they are represented.
[ ]:
files = os.listdir(DATA_DIR)
df = utils.load_data(os.path.join(DATA_DIR, files[0]))
df.head()
| start | stop | speaker | dialogue | |
|---|---|---|---|---|
| 0 | 00:00.00 | 00:06.00 | Tutor | All right. Do you see the tools on the left-ha... |
| 1 | 00:06.00 | 00:07.00 | Student | Yes. |
| 2 | 00:07.00 | 00:19.00 | Tutor | All right. We're going to take a look at those... |
| 3 | 00:19.00 | 00:31.00 | Tutor | So the third button down is a pencil. If you c... |
| 4 | 00:31.00 | 00:37.00 | Tutor | If you want to type anything, you can use the ... |
There are two speakers: one is the Tutor and the other is the Student. Let’s defined these variables as well.
[ ]:
STUDENT_SPEAKER = "Student"
TEACHER_SPEAKER = "Tutor"
📝 Text Pre-Processing and Annotation
Let’s first preprocess and annotate the dataset with edu-convokit. The following section will:
Read each file in the dataset and preprocess it using
edu-convokit’sPreprocessor.Then, annotate the file using
edu-convokit’sAnnotatorfor talktime, student reasoning and uptake.Finally, save the annotated file under
annotations/.
Let’s get started!
[ ]:
# Initialize the preprocessor and annotator
processor = TextPreprocessor()
annotator = Annotator()
# This takes about 20 minutes on Colab, CPU
# Though this time varies depending on bandwidth
for filename in tqdm.tqdm(os.listdir(DATA_DIR)):
if utils.is_valid_file_extension(filename):
df = utils.load_data(os.path.join(DATA_DIR, filename))
# Preprocess the data. We're just going to merge the utterances of the same speaker together and directly update the dataframe.
df = processor.merge_utterances_from_same_speaker(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
target_text_column=TEXT_COLUMN
)
# Now we're going to annotate the data.
df = annotator.get_talktime(
df=df,
text_column=TEXT_COLUMN,
output_column=TALK_TIME_COLUMN
)
df = annotator.get_student_reasoning(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
output_column=STUDENT_REASONING_COLUMN,
# We just want to annotate the student utterances. So we're going to specify the speaker value as STUDENT_SPEAKER.
speaker_value=STUDENT_SPEAKER
)
df = annotator.get_uptake(
df=df,
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
output_column=UPTAKE_COLUMN,
# We want to annotate the teacher's uptake of the student's utterances.
# So we're looking for instances where the student first speaks, then the teacher speaks.
speaker1=STUDENT_SPEAKER,
speaker2=TEACHER_SPEAKER
)
# And we're done! Let's now save the annotated data as a csv file.
filename = filename.split(".")[0] + ".csv"
df.to_csv(os.path.join(ANNOTATIONS_DIR, filename), index=False)
0%| | 0/45 [00:00<?, ?it/s]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
2%|▏ | 1/45 [00:20<14:55, 20.36s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
4%|▍ | 2/45 [00:58<22:12, 30.98s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
7%|▋ | 3/45 [01:20<18:45, 26.79s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
9%|▉ | 4/45 [01:52<19:38, 28.73s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
11%|█ | 5/45 [01:58<13:41, 20.53s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
13%|█▎ | 6/45 [02:25<14:42, 22.64s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
16%|█▌ | 7/45 [02:28<10:18, 16.29s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
18%|█▊ | 8/45 [03:00<13:15, 21.50s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
20%|██ | 9/45 [03:39<16:09, 26.93s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
22%|██▏ | 10/45 [03:43<11:30, 19.72s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
24%|██▍ | 11/45 [03:51<09:07, 16.10s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
27%|██▋ | 12/45 [03:54<06:43, 12.24s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
29%|██▉ | 13/45 [03:57<05:00, 9.40s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
31%|███ | 14/45 [04:09<05:18, 10.27s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
33%|███▎ | 15/45 [04:25<05:54, 11.82s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
36%|███▌ | 16/45 [04:46<07:09, 14.81s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
38%|███▊ | 17/45 [05:28<10:37, 22.77s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
40%|████ | 18/45 [06:30<15:38, 34.76s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
42%|████▏ | 19/45 [06:53<13:27, 31.06s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
44%|████▍ | 20/45 [07:20<12:29, 29.97s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
47%|████▋ | 21/45 [08:22<15:46, 39.42s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
49%|████▉ | 22/45 [08:44<13:10, 34.39s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
51%|█████ | 23/45 [08:51<09:30, 25.92s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
53%|█████▎ | 24/45 [09:26<10:05, 28.85s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
56%|█████▌ | 25/45 [10:05<10:34, 31.71s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
58%|█████▊ | 26/45 [10:26<09:03, 28.62s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
60%|██████ | 27/45 [10:30<06:21, 21.18s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
62%|██████▏ | 28/45 [11:01<06:49, 24.08s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
64%|██████▍ | 29/45 [12:14<10:19, 38.75s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
67%|██████▋ | 30/45 [12:41<08:50, 35.35s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
69%|██████▉ | 31/45 [13:56<11:01, 47.25s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
71%|███████ | 32/45 [14:21<08:46, 40.48s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
73%|███████▎ | 33/45 [14:24<05:50, 29.20s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
76%|███████▌ | 34/45 [14:38<04:33, 24.84s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
78%|███████▊ | 35/45 [15:15<04:42, 28.26s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
80%|████████ | 36/45 [15:52<04:40, 31.12s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
82%|████████▏ | 37/45 [16:12<03:40, 27.60s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
84%|████████▍ | 38/45 [16:35<03:04, 26.38s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
87%|████████▋ | 39/45 [16:53<02:22, 23.68s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
89%|████████▉ | 40/45 [16:55<01:27, 17.43s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
91%|█████████ | 41/45 [17:28<01:28, 22.06s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
93%|█████████▎| 42/45 [17:57<01:12, 24.07s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
96%|█████████▌| 43/45 [18:21<00:47, 23.87s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
98%|█████████▊| 44/45 [18:53<00:26, 26.48s/it]WARNING:root:Note: This model was trained on student reasoning, so it should be used on student utterances.
For more details on the model, see https://arxiv.org/pdf/2211.11772.pdf
WARNING:root:Note: This model was trained on teacher's uptake of student's utterances. So, speaker1 should be the student and speaker2 should be the teacher.
For more details on the model, see https://arxiv.org/pdf/2106.03873.pdf
WARNING:root:Note: It's recommended that you merge utterances from the same speaker before running this model. You can do that with edu_convokit.text_preprocessing.merge_utterances_from_same_speaker.
100%|██████████| 45/45 [19:02<00:00, 25.38s/it]
Analysis
Now that we have annotated the dataset, let’s analyze it using edu-convokit’s Analyzer. We’ll be doing the following:
We’ll use
QualitativeAnalyzerto look at some examples of the talktime, student reasoning and uptake annotations.We’ll use
QuantitativeAnalyzerto look at the aggregate statistics of the talktime, student reasoning and uptake annotations.We’ll use
LexicalAnalyzerto compare the student and tutor’s vocabulary.We’ll use
TemporalAnalyzerto look at the temporal trends of the talktime, student reasoning and uptake annotations.
Let’s get started!!!
🔍 Qualitative Analysis
[ ]:
# We're going to look at examples from the entire dataset.
qualitative_analyzer = QualitativeAnalyzer(data_dir=ANNOTATIONS_DIR)
# Examples of talktime. Will show random examples from the dataset.
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=TALK_TIME_COLUMN,
)
talktime: 34
>> Tutor: Okay, we're going to be talking back and forth like this, so you can close your chat box if you would like, and that'll open up your screen so you have more work space.
talktime: 34
>> Tutor: So I understand what you're thinking. Don't worry about changing those dots. What is? where are you? Though, most likely that's causing you to be in stop and go traffic from D to E.
talktime: 34
>> Tutor: We're going to look at just those three sections, A to b, B to c, C to D, and just those three sections of the graph. I'd like you to sketch a new graph.
talktime: 1
>> Student: Then.
talktime: 1
>> Student: At.
talktime: 1
>> Student: But
talktime: 11
>> Tutor: On the lefthand side of your screen, you see some tools.
talktime: 11
>> Student: The distance by hour, like how far they're moving per hour.
talktime: 11
>> Tutor: Is that point a a break? Is that what you just?
[ ]:
# Examples of student reasoning. Let's look at positive examples:
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=STUDENT_REASONING_COLUMN,
feature_value=1.0,
)
student_reasoning: 1.0
>> Student: Um, maybe like they're measuring how far or how long it would take to get from Providence to Newark.
student_reasoning: 1.0
>> Student: Uh, it's similar'cause the two different units I was talking about miles and hours and they're measuring the distance.
student_reasoning: 1.0
>> Student: I'll just say A lo, Um, from A to B. it's increasing, and from B to C. it's staying the same from C to D. It's increasing from Dt. it's increasing.
[ ]:
# We can also look at negative examples:
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=STUDENT_REASONING_COLUMN,
feature_value=0.0,
)
student_reasoning: 0.0
>> Student: Um, how many miles per hour the car is driving?
student_reasoning: 0.0
>> Student: The distance by hour, like how far they're moving per hour.
student_reasoning: 0.0
>> Student: Uh, the mileage I think, is it? Ah, I do't.
[ ]:
# Examples of uptake.
qualitative_analyzer.print_examples(
speaker_column=SPEAKER_COLUMN,
text_column=TEXT_COLUMN,
feature_column=UPTAKE_COLUMN,
# I want to look at positive examples of uptake (uptake = 1.0)
feature_value=1.0,
# ... and look at the previous student utterance (show_k_previous_lines = 1).
# This is interesting because it will show us how the teacher is responding to the student's utterance.
show_k_previous_lines=1,
)
uptake: 1.0
Student: Um, maybe like they're measuring how far or how long it would take to get from Providence to Newark.
>> Tutor: Cool if they're measuring how far or how long what units would they be using to?
uptake: 1.0
Student: Um, how many miles per hour the car is driving?
>> Tutor: Wo mile per hour be keeping track of.
uptake: 1.0
Student: The distance by hour, like how far they're moving per hour.
>> Tutor: Ah, and do you know how else we can describe that? What's that thing that we're talking about with the car? if we're describing how far per hour it's going?
📊 Quantitative Analysis
[ ]:
quantitative_analyzer = QuantitativeAnalyzer(data_dir=ANNOTATIONS_DIR)
# Let's plot the talk time ratio between the speakers.
quantitative_analyzer.plot_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
# Proportion of talk time for each speaker.
value_as="prop"
)
# We can also print the statistics:
quantitative_analyzer.print_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
# Proportion of talk time for each speaker.
value_as="prop"
)
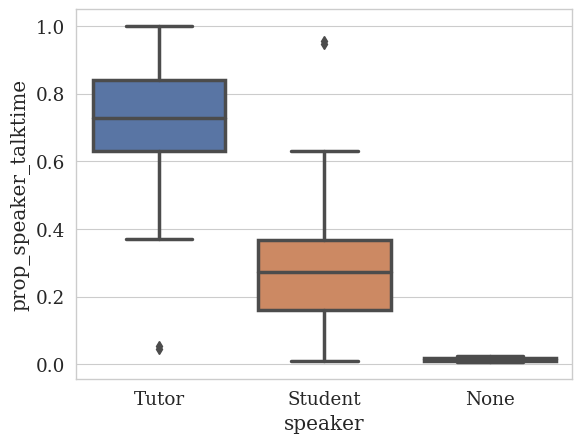
talktime
Proportion statistics
count mean std min 25% 50% 75% max
speaker
None 2.0 0.014643 0.012308 0.005940 0.010291 0.014643 0.018995 0.023346
Student 44.0 0.304822 0.213351 0.009091 0.159112 0.272535 0.367901 0.955194
Tutor 45.0 0.701301 0.215427 0.044806 0.631480 0.727766 0.840467 1.000000
<Figure size 640x480 with 0 Axes>
[ ]:
# What about the student reasoning? How often does the student use reasoning?
quantitative_analyzer.plot_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
# We change this to "avg" because we're now looking at within-speaker statistics.
value_as="avg",
# We can set the y-axis limits to [0, 1] because the student reasoning column is a binary column.
yrange=(0, 1)
)
# We can also print the statistics:
quantitative_analyzer.print_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg"
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
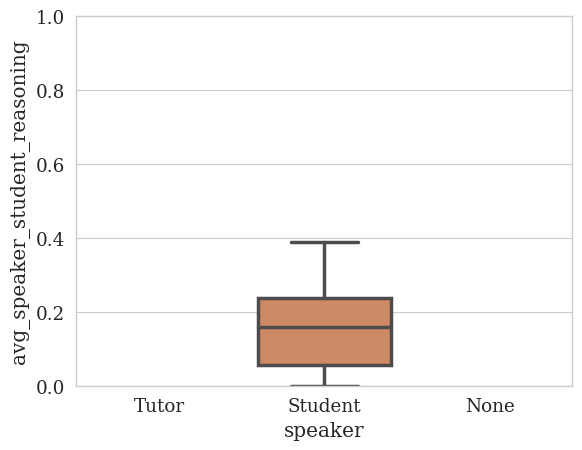
student_reasoning
Average statistics
count mean std min 25% 50% 75% max
speaker
None 0.0 NaN NaN NaN NaN NaN NaN NaN
Student 38.0 0.154413 0.114317 0.0 0.056493 0.158859 0.238824 0.388889
Tutor 0.0 NaN NaN NaN NaN NaN NaN NaN
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
<Figure size 640x480 with 0 Axes>
Note, the tutor has no student_reasoning because we did not annotate the tutor’s utterances for student reasoning. We can easily remove the tutor from the plot by dropping na values:
[ ]:
quantitative_analyzer.plot_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
yrange=(0, 1),
dropna=True
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
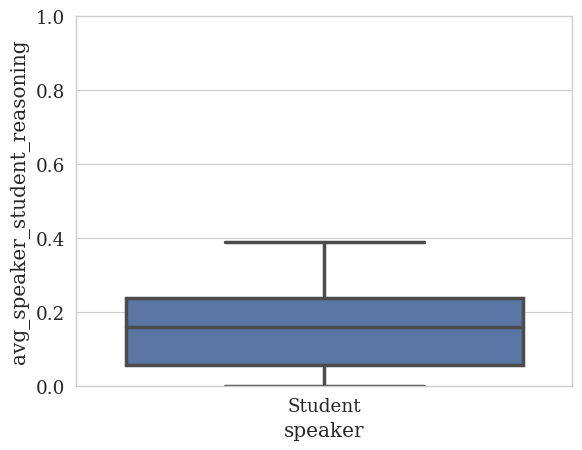
<Figure size 640x480 with 0 Axes>
[ ]:
# Finally, let's look at the tutor's uptake of the student's utterances.
quantitative_analyzer.plot_statistics(
feature_column=UPTAKE_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
yrange=(0, 1),
dropna=True
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/quantitative_analyzer.py:51: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
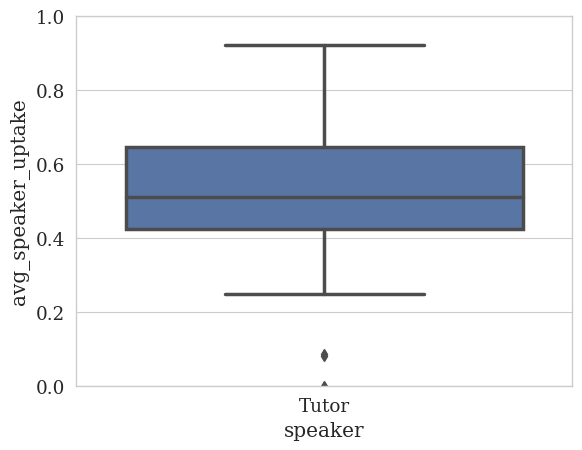
<Figure size 640x480 with 0 Axes>
💬 Lexical Analysis
[ ]:
lexical_analyzer = LexicalAnalyzer(data_dir=ANNOTATIONS_DIR)
# Let's look at the most common words per speaker in the dataset.
lexical_analyzer.print_word_frequency(
text_column=TEXT_COLUMN,
speaker_column=SPEAKER_COLUMN,
# We want to look at the top 10 words per speaker.
topk=10,
# Let's also format the text (e.g., remove punctuation, lowercase the text, etc.)
run_text_formatting=True
)
Top Words By Speaker
Tutor
going: 942
miles: 929
okay: 810
like: 789
speed: 727
hour: 715
time: 711
car: 668
yeah: 620
graph: 579
Student
like: 1367
miles: 780
hour: 660
yeah: 564
would: 474
okay: 434
fifty: 431
point: 428
distance: 423
think: 411
None
okay: 4
cool: 1
yeah: 1
average: 1
make: 1
sense: 1
yep: 1
three: 1
four: 1
yes: 1
The language between the two looks pretty similar. Let’s run a log-odds analysis to see what words that are more likely to be used by the tutor vs. student.
[ ]:
# This returns the merged dataframe of the annotated files in DATA_DIR.
df = lexical_analyzer.get_df()
# We want to create two groups of df: one for the student and one for the tutor.
student_df = df[df[SPEAKER_COLUMN] == STUDENT_SPEAKER]
tutor_df = df[df[SPEAKER_COLUMN] == TEACHER_SPEAKER]
# Now we can run the log-odds analysis:
lexical_analyzer.plot_log_odds(
df1=student_df,
df2=tutor_df,
text_column1=TEXT_COLUMN,
text_column2=TEXT_COLUMN,
# Let's name the df groups to show on the plot
group1_name="Student",
group2_name="Tutor",
# Let's also run the text formatting
run_text_formatting=True,
)

<Figure size 640x480 with 0 Axes>
[ ]:
# We might also be interested in other n-grams. Let's look at the top 10 bigrams per speaker.
lexical_analyzer.plot_log_odds(
df1=student_df,
df2=tutor_df,
text_column1=TEXT_COLUMN,
text_column2=TEXT_COLUMN,
group1_name="Student",
group2_name="Tutor",
run_text_formatting=True,
# n-grams:
run_ngrams=True,
n=2,
topk=10
)
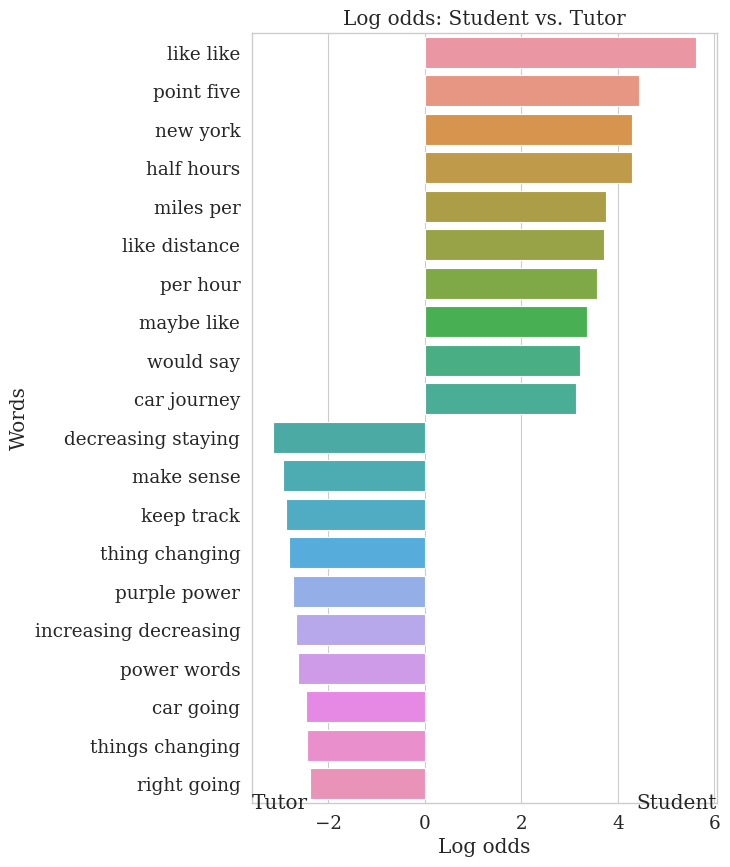
<Figure size 640x480 with 0 Axes>
📈 Temporal Analysis
Let’s look at the temporal trends of the talktime, student reasoning and uptake annotations!
[ ]:
temporal_analyzer = TemporalAnalyzer(data_dir=ANNOTATIONS_DIR)
# First let's look at the talk time ratio between the speakers over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=TALK_TIME_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="prop",
# Let's create 10 bins for the x-axis.
num_bins=10
)

<Figure size 640x480 with 0 Axes>
[ ]:
# Now student reasoning over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=STUDENT_REASONING_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
# Let's create 10 bins for the x-axis.
num_bins=10,
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/temporal_analyzer.py:57: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,
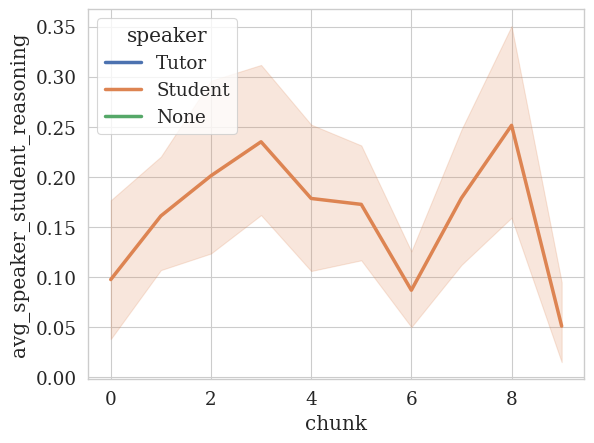
<Figure size 640x480 with 0 Axes>
[ ]:
# Finally, let's look at the tutor's uptake of the student's utterances over time.
temporal_analyzer.plot_temporal_statistics(
feature_column=UPTAKE_COLUMN,
speaker_column=SPEAKER_COLUMN,
value_as="avg",
# Let's create 10 bins for the x-axis.
num_bins=10,
)
/usr/local/lib/python3.10/dist-packages/edu_convokit/analyzers/temporal_analyzer.py:57: RuntimeWarning: invalid value encountered in double_scalars
f"prop_speaker_{feature_column}": speaker_df[feature_column].sum() / feature_sum,

<Figure size 640x480 with 0 Axes>
📚 Conclusions and Next Steps
Great! From this tutorial, we learned how to use edu-convokit to preprocess, annotate and analyze the Amber dataset. We saw how very simple principles built into edu-convokit can be used to analyze the dataset and gain insights into the data from various perspectives (qualitative, quantitative, lexical and temporal).
Other resources you can check out include:
`edu-convokitdocumentation <https://edu-convokit.readthedocs.io/en/latest/>`__`edu-convokitGitHub repository <https://github.com/rosewang2008/edu-convokit/tree/main>`__
If you have any questions, please feel free to reach out to us on `edu-convokit’s GitHub <https://github.com/rosewang2008/edu-convokit>`__.
👋 Happy exploring your data with edu-convokit!